
如何部署Deepseek?Deepseek部署教程
一、下载Ollama
使用Ollama可以大大降低显存需求,消费级的显卡也能运行大模型,首先我们进入官网下载:https://ollama.com/download
选择windows版本

安装完成之后,可以看到右下角的状态栏中会显示Ollama的图标:

二、下载DeepSeek-R1模型
进入Ollama官网,找到Models标签,可以看到第一个就是DeepSeek-R1:


点进去以后,可以在下方选择模型的参数规模,每个模型右边则是模型的大小,如果是8g的显卡,可以选择7b或者8b的模型。这里以3060 12g为例,下载14b的模型:

然后复制右侧命令:ollama run deepseek-r1
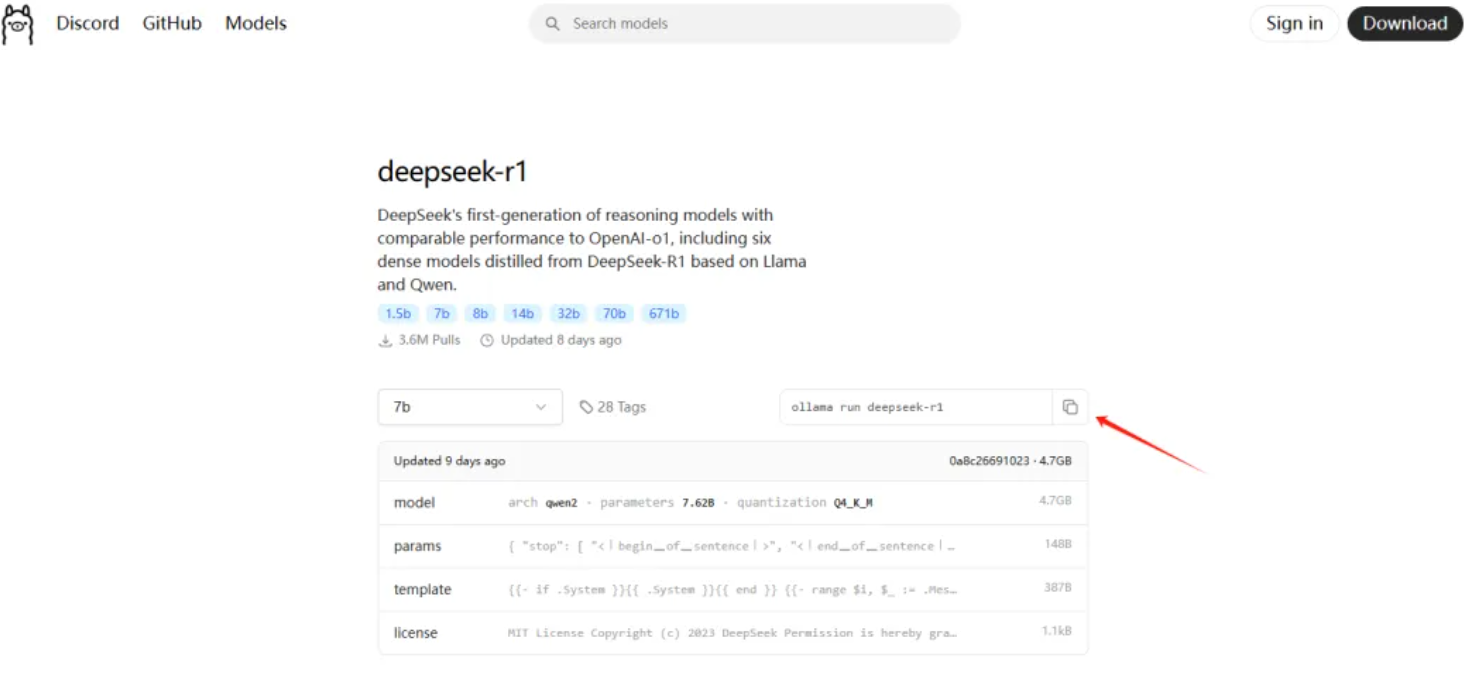
打开电脑终端,键盘上按win+R,输入cmd,进入命令行:

输入刚才复制的命令,下载大模型
Ollama模型的存储目录是这样的:

若系统盘(C盘)空间不足,可通过设置环境变量将OLLAMA_MODELS指向其他存储路径,把它设置为所选目录,参考:https://github.com/ollama/ollama/blob/main/docs/faq.md。
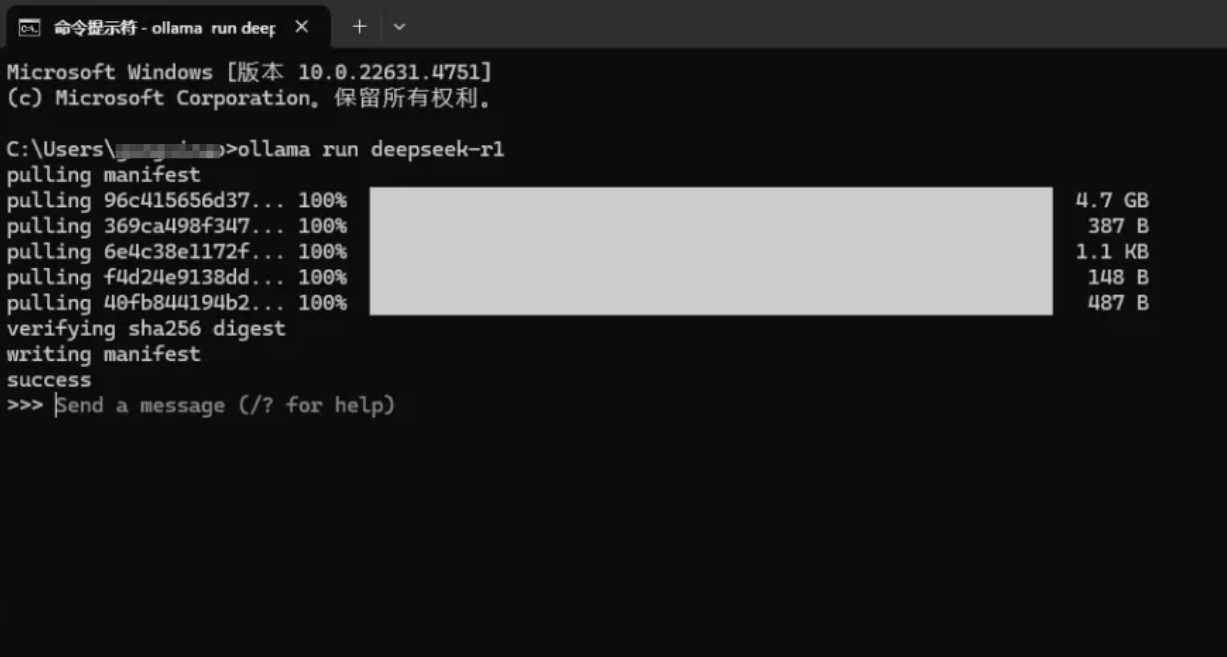
100%即模型下载完毕。
三、命令行对话
下载完模型以后,直接进入对话界面,可以直接在命令行对话聊天,标签内是深度思考的内容:

可视化本地大模型安装
方式一
安装一个可视化对话Chatbox
下载安装https://chatboxai.app/zh

配置上Ollama,打开Chatbox
点击设置,选择模型提供方

选择模型保存
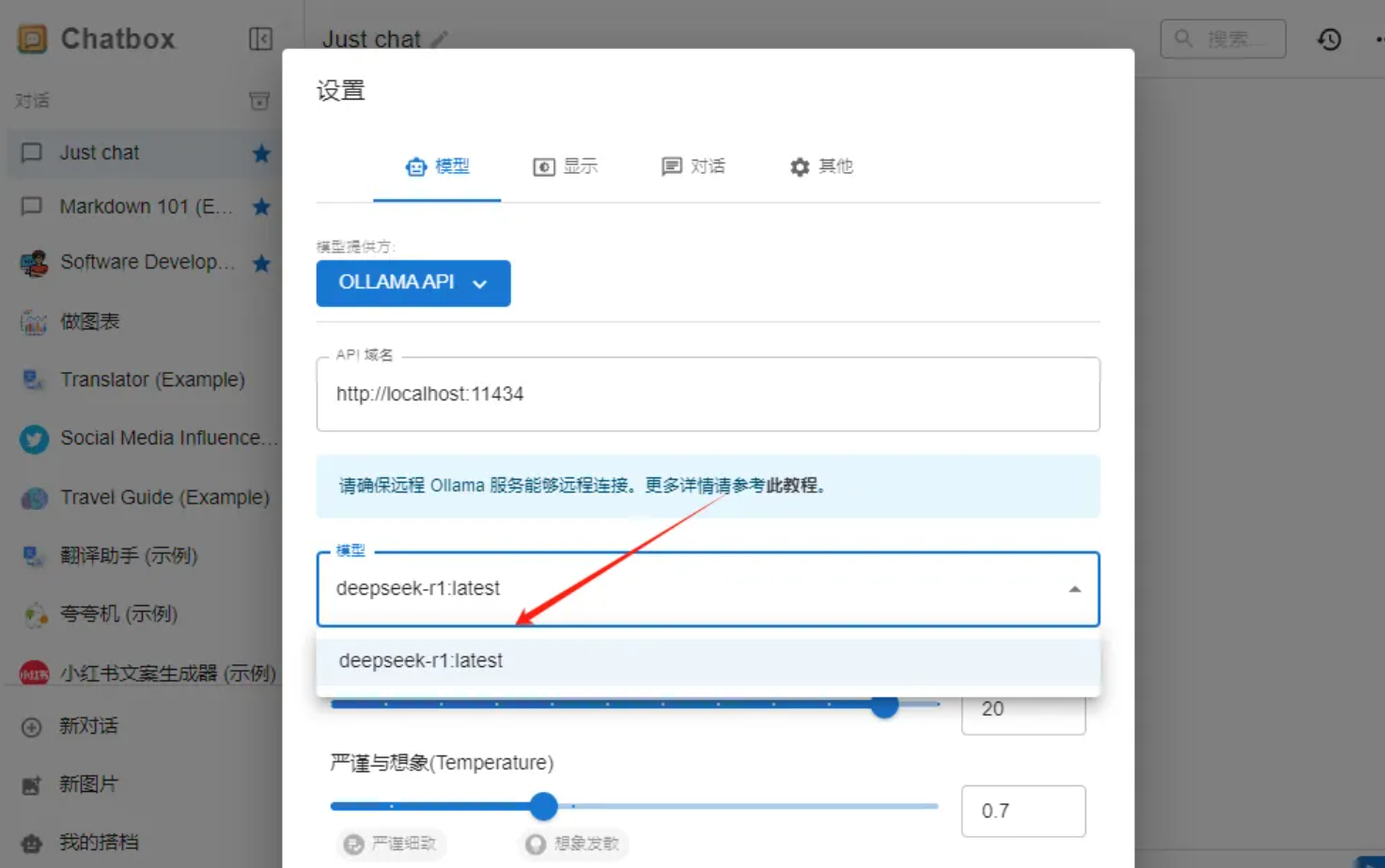
此时可以使用DeepSeek

方式二
docker安装, https://docs.docker.com/desktop/release-notes/
选择
双击运行

安装完成

安装之后可以重启。

打开命令行输出docker出现以上界面docker安装成功。
首先打开docker


命令行运行的界面可能不够美观和易用,如果想要在网页端更便捷地使用,可以选择用NextChat可视化运行。
首先,进入open-webui主页https://github.com/open-webui/open-webui,找到下载链接。由于我们已经安装过Ollama,所以可以选择第一条指令,点击右侧的复制:

docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main

出现上图docker镜像拉取完成。
安装完成后,点击docker中对应的网址,就可以访问了:
打开docker

访问http://localhost:3000/auth

创建本地账号

登录之后选择我们的deepseek
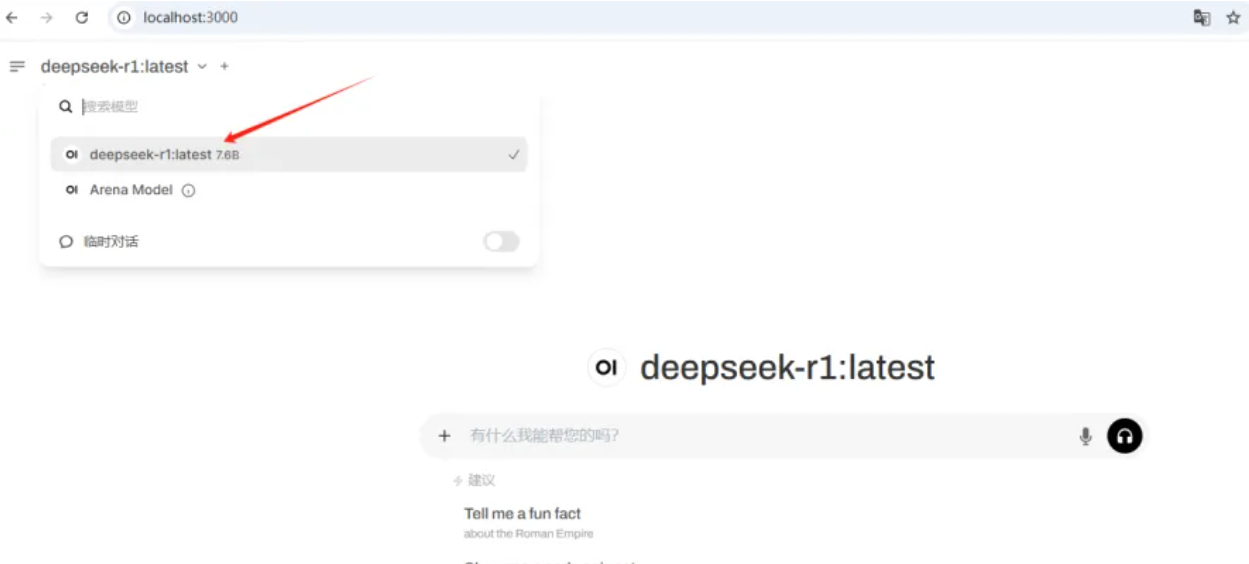
此时可以正常使用

注意在docker容器启动的过程中可能会有卡顿现象,此时等待几分钟即可。
如果不需要使用本地大模型,在docker中将容器关掉即可,下次使用可以打开。




